mirror of
https://git.mirrors.martin98.com/https://github.com/infiniflow/ragflow.git
synced 2025-08-10 19:08:58 +08:00
Updated RAPTOR-specific UI (#7348)
### What problem does this PR solve? ### Type of change - [x] Documentation Update
This commit is contained in:
parent
a4be6c50cf
commit
43e507d554
@ -21,7 +21,7 @@ Enabling RAPTOR requires significant memory, computational resources, and tokens
|
||||
|
||||
## Basic principles
|
||||
|
||||
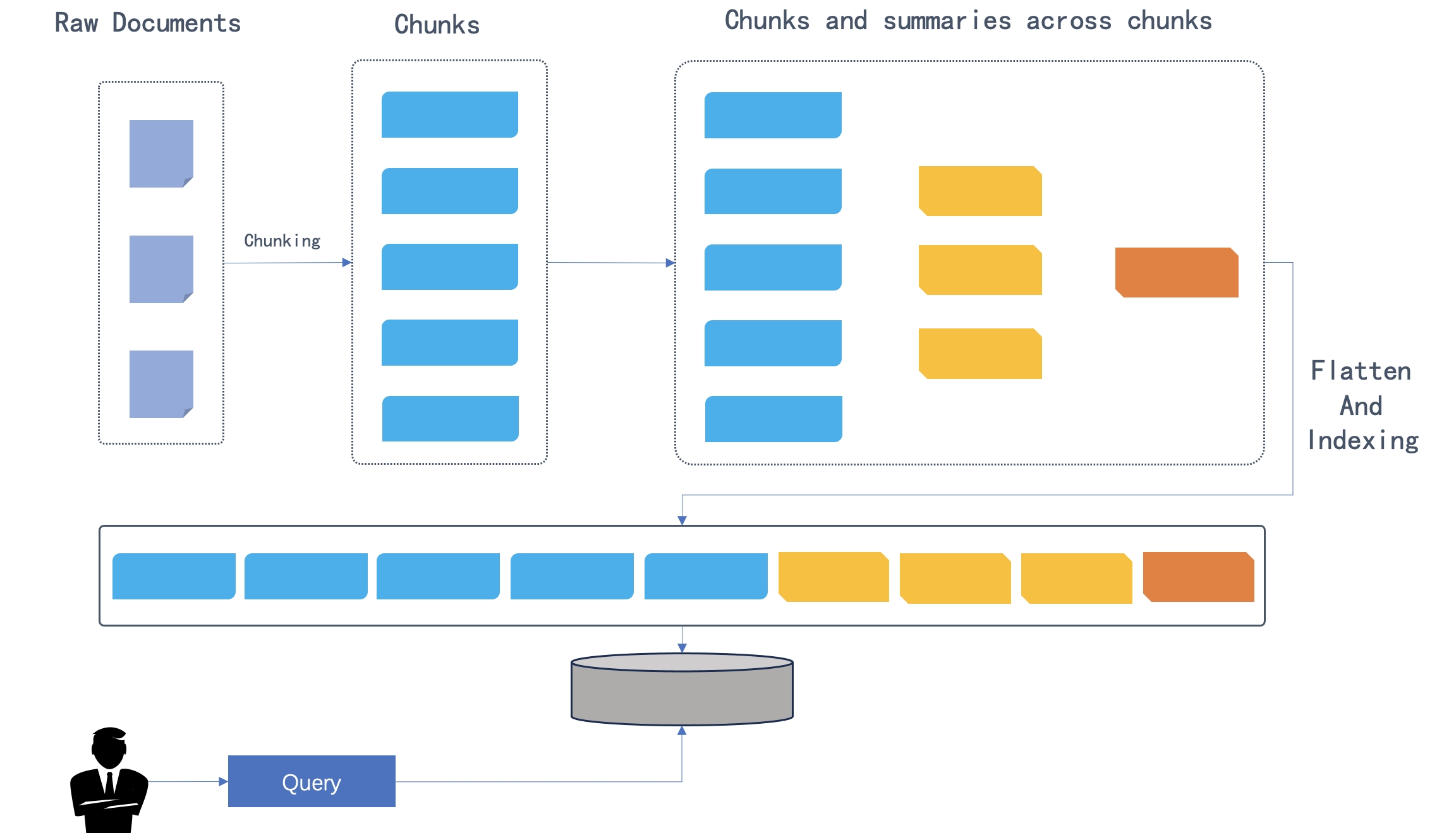
After the original documents are divided into chunks, the chunks are clustered by semantic similarity rather than by their original order in the text. Clusters are then summarized into higher-level chunks by your system's default chat model. This process is applied recursively, forming a tree structure with various levels of summarization from the bottom up. As illustrated in the figure below, the initial chunks form the leaf nodes (shown in blue) and are progressively summarized into a root node (shown in orange).
|
||||
After the original documents are divided into chunks, the chunks are clustered by semantic similarity rather than by their original order in the text. Clusters are then summarized into higher-level chunks by your system's default chat model. This process is applied recursively, forming a tree structure with various levels of summarization from the bottom up. As illustrated in the figure below, the initial chunks form the leaf nodes (shown in blue) and are recursively summarized into a root node (shown in orange).
|
||||
|
||||
|
||||
|
||||
|
||||
@ -342,14 +342,14 @@ export default {
|
||||
{cluster_content}
|
||||
Das oben Genannte ist der Inhalt, den Sie zusammenfassen müssen.`,
|
||||
maxToken: 'Maximale Token',
|
||||
maxTokenTip: 'Maximale Token-Anzahl für die Zusammenfassung.',
|
||||
maxTokenTip: 'Die maximale Anzahl an Token pro generiertem Zusammenfassungs-Chunk.',
|
||||
maxTokenMessage: 'Maximale Token sind erforderlich',
|
||||
threshold: 'Schwellenwert',
|
||||
thresholdTip:
|
||||
'Je größer der Schwellenwert, desto weniger Cluster werden erzeugt.',
|
||||
'In RAPTOR werden Chunks anhand ihrer semantischen Ähnlichkeit gruppiert. Der Schwellenwert-Parameter legt die minimale Ähnlichkeit fest, die erforderlich ist, damit Chunks zusammengefasst werden. Ein höherer Schwellenwert bedeutet weniger Chunks pro Cluster, während ein niedrigerer Wert mehr Chunks pro Cluster zulässt.',
|
||||
thresholdMessage: 'Schwellenwert ist erforderlich',
|
||||
maxCluster: 'Maximale Cluster',
|
||||
maxClusterTip: 'Maximale Cluster-Anzahl.',
|
||||
maxClusterTip: 'Die maximale Anzahl der zu erstellenden Cluster.',
|
||||
maxClusterMessage: 'Maximale Cluster sind erforderlich',
|
||||
randomSeed: 'Zufallszahl',
|
||||
randomSeedMessage: 'Zufallszahl ist erforderlich',
|
||||
|
||||
@ -334,13 +334,13 @@ export default {
|
||||
{cluster_content}
|
||||
The above is the content you need to summarize.`,
|
||||
maxToken: 'Max token',
|
||||
maxTokenTip: 'Maximum token number for summarization.',
|
||||
maxTokenTip: 'The maximum number of tokens per generated summary chunk.',
|
||||
maxTokenMessage: 'Max token is required',
|
||||
threshold: 'Threshold',
|
||||
thresholdTip: 'The bigger the threshold is the less cluster will be.',
|
||||
thresholdTip: 'In RAPTOR, chunks are clustered by their semantic similarity. The Threshold parameter sets the minimum similarity required for chunks to be grouped together. A higher Threshold means fewer chunks in each cluster, while a lower one means more.',
|
||||
thresholdMessage: 'Threshold is required',
|
||||
maxCluster: 'Max cluster',
|
||||
maxClusterTip: 'Maximum cluster number.',
|
||||
maxClusterTip: 'The maximum number of clusters to create.',
|
||||
maxClusterMessage: 'Max cluster is required',
|
||||
randomSeed: 'Random seed',
|
||||
randomSeedMessage: 'Random seed is required',
|
||||
|
||||
@ -298,14 +298,14 @@ export default {
|
||||
{cluster_content}
|
||||
Di atas adalah konten yang perlu Anda rangkum.`,
|
||||
maxToken: 'Token maksimum',
|
||||
maxTokenTip: 'Jumlah token maksimum untuk peringkasan.',
|
||||
maxTokenTip: 'Jumlah maksimum token per potongan ringkasan yang dihasilkan.',
|
||||
maxTokenMessage: 'Token maksimum diperlukan',
|
||||
threshold: 'Ambang batas',
|
||||
thresholdTip:
|
||||
'Semakin besar ambang batas, semakin sedikit kluster yang akan ada.',
|
||||
'Dalam RAPTOR, potongan-potongan dikelompokkan berdasarkan kemiripan semantiknya. Parameter Ambang menetapkan tingkat kemiripan minimum yang diperlukan agar potongan-potongan dapat dikelompokkan bersama. Ambang yang lebih tinggi berarti lebih sedikit potongan dalam setiap kelompok, sedangkan ambang yang lebih rendah berarti lebih banyak potongan dalam satu kelompok.',
|
||||
thresholdMessage: 'Ambang batas diperlukan',
|
||||
maxCluster: 'Kluster maksimum',
|
||||
maxClusterTip: 'Jumlah kluster maksimum.',
|
||||
maxClusterTip: 'Jumlah maksimum klaster yang akan dibuat.',
|
||||
maxClusterMessage: 'Kluster maksimum diperlukan',
|
||||
randomSeed: 'Benih acak',
|
||||
randomSeedMessage: 'Benih acak diperlukan',
|
||||
|
||||
@ -293,13 +293,13 @@ export default {
|
||||
{cluster_content}
|
||||
上記が要約する内容です。`,
|
||||
maxToken: '最大トークン数',
|
||||
maxTokenTip: '要約のための最大トークン数。',
|
||||
maxTokenTip: '生成された要約チャンクごとの最大トークン数。',
|
||||
maxTokenMessage: '最大トークン数は必須です',
|
||||
threshold: 'しきい値',
|
||||
thresholdTip: 'しきい値が大きいほどクラスターは少なくなります。',
|
||||
thresholdTip: 'RAPTORでは、チャンクは意味的な類似性によってクラスタリングされます。しきい値パラメータは、チャンクをまとめるために必要な最小限の類似度を設定します。しきい値が高いほど各クラスタ内のチャンク数は少なくなり、しきい値が低いほど多くのチャンクが1つのクラスタに含まれます。',
|
||||
thresholdMessage: 'しきい値は必須です',
|
||||
maxCluster: '最大クラスター数',
|
||||
maxClusterTip: '最大クラスター数。',
|
||||
maxClusterTip: '作成するクラスタの最大数。',
|
||||
maxClusterMessage: '最大クラスター数は必須です',
|
||||
randomSeed: 'ランダムシード',
|
||||
randomSeedMessage: 'ランダムシードは必須です',
|
||||
|
||||
@ -270,13 +270,13 @@ export default {
|
||||
{cluster_content}
|
||||
O conteúdo acima precisa ser resumido.`,
|
||||
maxToken: 'Máximo de tokens',
|
||||
maxTokenTip: 'Número máximo de tokens para sumarização.',
|
||||
maxTokenTip: 'O número máximo de tokens por chunk de resumo gerado.',
|
||||
maxTokenMessage: 'O número máximo de tokens é obrigatório',
|
||||
threshold: 'Limite',
|
||||
thresholdTip: 'Quanto maior o limite, menor será o número de clusters.',
|
||||
thresholdTip: 'No RAPTOR, os chunks são agrupados de acordo com sua similaridade semântica. O parâmetro de Limite define a similaridade mínima necessária para que os chunks sejam agrupados. Um Limite mais alto significa menos chunks em cada grupo, enquanto um Limite mais baixo significa mais chunks por grupo.',
|
||||
thresholdMessage: 'O limite é obrigatório',
|
||||
maxCluster: 'Máximo de clusters',
|
||||
maxClusterTip: 'Número máximo de clusters.',
|
||||
maxClusterTip: 'O número máximo de clusters a serem criados.',
|
||||
maxClusterMessage: 'O número máximo de clusters é obrigatório',
|
||||
randomSeed: 'Semente aleatória',
|
||||
randomSeedMessage: 'A semente aleatória é obrigatória',
|
||||
|
||||
@ -303,13 +303,13 @@ export default {
|
||||
{cluster_content}
|
||||
Nội dung ở trên là nội dung bạn cần tóm tắt.`,
|
||||
maxToken: 'Số token tối đa',
|
||||
maxTokenTip: 'Số lượng token tối đa để tóm tắt.',
|
||||
maxTokenTip: 'Số lượng token tối đa cho mỗi đoạn tóm tắt được tạo ra.',
|
||||
maxTokenMessage: 'Số token tối đa là bắt buộc',
|
||||
threshold: 'Ngưỡng',
|
||||
thresholdTip: 'Ngưỡng càng cao thì cụm càng ít.',
|
||||
thresholdTip: 'Trong RAPTOR, các đoạn văn bản được nhóm lại dựa trên sự tương đồng ngữ nghĩa của chúng. Tham số Ngưỡng thiết lập mức độ tương đồng tối thiểu cần thiết để các đoạn được nhóm lại với nhau. Ngưỡng càng cao thì mỗi nhóm sẽ có ít đoạn hơn, còn ngưỡng càng thấp thì mỗi nhóm sẽ có nhiều đoạn hơn.',
|
||||
thresholdMessage: 'Ngưỡng là bắt buộc',
|
||||
maxCluster: 'Cụm tối đa',
|
||||
maxClusterTip: 'Số lượng cụm tối đa.',
|
||||
maxClusterTip: 'Số lượng cụm tối đa được tạo ra.',
|
||||
maxClusterMessage: 'Cụm tối đa là bắt buộc',
|
||||
randomSeed: 'Hạt giống ngẫu nhiên',
|
||||
randomSeedMessage: 'Hạt giống ngẫu nhiên là bắt buộc',
|
||||
|
||||
@ -331,9 +331,9 @@ export default {
|
||||
randomSeedMessage: '隨機種子是必填項',
|
||||
promptTip:
|
||||
'系統提示為大型模型提供任務描述、規定回覆方式,以及設定其他各種要求。系統提示通常與 key(變數)合用,透過變數設定大型模型的輸入資料。你可以透過斜線或 (x) 按鈕顯示可用的 key。',
|
||||
maxTokenTip: '用於匯總的最大token數。',
|
||||
thresholdTip: '閾值越大,聚類越少。',
|
||||
maxClusterTip: '最大聚類數。',
|
||||
maxTokenTip: '用於設定每個被總結的文字塊的最大 token 數。',
|
||||
thresholdTip: '在 RAPTOR 中,數據塊會根據它們的語義相似性進行聚類。閾值參數設定了數據塊被分到同一組所需的最小相似度。閾值越高,每個聚類中的數據塊越少;閾值越低,則每個聚類中的數據塊越多。',
|
||||
maxClusterTip: '最多可創建的聚類數。',
|
||||
entityTypes: '實體類型',
|
||||
pageRank: '頁面排名',
|
||||
pageRankTip: `知識庫檢索時,你可以為特定知識庫設置較高的 PageRank 分數,該知識庫中匹配文本塊的混合相似度得分會自動疊加 PageRank 分數,從而提升排序權重。詳見 https://ragflow.io/docs/dev/set_page_rank。`,
|
||||
|
||||
@ -348,9 +348,9 @@ export default {
|
||||
randomSeedMessage: '随机种子是必填项',
|
||||
promptTip:
|
||||
'系统提示为大模型提供任务描述、规定回复方式,以及设置其他各种要求。系统提示通常与 key (变量)合用,通过变量设置大模型的输入数据。你可以通过斜杠或者 (x) 按钮显示可用的 key。',
|
||||
maxTokenTip: '用于汇总的最大token数。',
|
||||
thresholdTip: '阈值越大,聚类越少。',
|
||||
maxClusterTip: '最大聚类数。',
|
||||
maxTokenTip: '用于设定每个被总结的文本块的最大 token 数。',
|
||||
thresholdTip: '在 RAPTOR 中,数据块会根据它们的语义相似性进行聚类。阈值设定了数据块被分到同一组所需的最小相似度。阈值越高,每个聚类中的数据块越少;阈值越低,则每个聚类中的数据块越多。',
|
||||
maxClusterTip: '最多可创建的聚类数。',
|
||||
entityTypes: '实体类型',
|
||||
pageRank: '页面排名',
|
||||
pageRankTip: `知识库检索时,你可以为特定知识库设置较高的 PageRank 分数,该知识库中匹配文本块的混合相似度得分会自动叠加 PageRank 分数,从而提升排序权重。详见 https://ragflow.io/docs/dev/set_page_rank。`,
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user