mirror of
https://git.mirrors.martin98.com/https://github.com/infiniflow/ragflow.git
synced 2025-07-19 17:54:29 +08:00
0519 pdfparser (#7747)
### What problem does this PR solve? ### Type of change - [x] Documentation Update
This commit is contained in:
parent
1c6320828c
commit
76b278af8e
@ -23,7 +23,7 @@ Once a connection is established, an MCP server communicates with its client in
|
||||
## Prerequisites
|
||||
|
||||
1. Ensure RAGFlow is upgraded to v0.18.0 or later.
|
||||
2. Have your RAGFlow API key ready. See [Acquire a RAGFlow API key](./acquire_ragflow_api_key.md).
|
||||
2. Have your RAGFlow API key ready. See [Acquire a RAGFlow API key](../acquire_ragflow_api_key.md).
|
||||
|
||||
:::tip INFO
|
||||
If you wish to try out our MCP server without upgrading RAGFlow, community contributor [yiminghub2024](https://github.com/yiminghub2024) 👏 shares their recommended steps [here](#launch-an-mcp-server-without-upgrading-ragflow).
|
||||
|
||||
@ -11,7 +11,7 @@ Switch your doc engine from Elasticsearch to Infinity.
|
||||
|
||||
RAGFlow uses Elasticsearch by default for storing full text and vectors. To switch to [Infinity](https://github.com/infiniflow/infinity/), follow these steps:
|
||||
|
||||
:::danger WARNING
|
||||
:::caution WARNING
|
||||
Switching to Infinity on a Linux/arm64 machine is not yet officially supported.
|
||||
:::
|
||||
|
||||
@ -21,7 +21,7 @@ Switching to Infinity on a Linux/arm64 machine is not yet officially supported.
|
||||
$ docker compose -f docker/docker-compose.yml down -v
|
||||
```
|
||||
|
||||
:::cautiion WARNING
|
||||
:::caution WARNING
|
||||
`-v` will delete the docker container volumes, and the existing data will be cleared.
|
||||
:::
|
||||
|
||||
|
||||
@ -25,7 +25,7 @@ When debugging your chat assistant, you can use AI search as a reference to veri
|
||||
|
||||
## Frequently asked questions
|
||||
|
||||
### key difference between an AI search and an AI chat?
|
||||
### Key difference between an AI search and an AI chat?
|
||||
|
||||
A chat is a multi-turn AI conversation where you can define your retrieval strategy (a weighted reranking score can be used to replace the weighted vector similarity in a hybrid search) and choose your chat model. In an AI chat, you can configure advanced RAG strategies, such as knowledge graphs, auto-keyword, and auto-question, for your specific case. Retrieved chunks are not displayed along with the answer.
|
||||
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
---
|
||||
sidebar_position: 0
|
||||
sidebar_position: -1
|
||||
slug: /configure_knowledge_base
|
||||
---
|
||||
|
||||
|
||||
53
docs/guides/dataset/select_pdf_parser.md
Normal file
53
docs/guides/dataset/select_pdf_parser.md
Normal file
@ -0,0 +1,53 @@
|
||||
---
|
||||
sidebar_position: 0
|
||||
slug: /select_pdf_parser
|
||||
---
|
||||
|
||||
# Select PDF parser
|
||||
|
||||
Select a visual model for parsing your PDFs.
|
||||
|
||||
---
|
||||
|
||||
RAGFlow isn't one-size-fits-all. It is built for flexibility and supports deeper customization to accommodate more complex use cases. From v0.17.0 onwards, RAGFlow decouples DeepDoc-specific data extraction tasks from chunking methods **for PDF files**. This separation enables you to autonomously select a visual model for OCR (Optical Character Recognition), TSR (Table Structure Recognition), and DLR (Document Layout Recognition) tasks that balances speed and performance to suit your specific use cases. If your PDFs contain only plain text, you can opt to skip these tasks by selecting the **Naive** option, to reduce the overall parsing time.
|
||||
|
||||
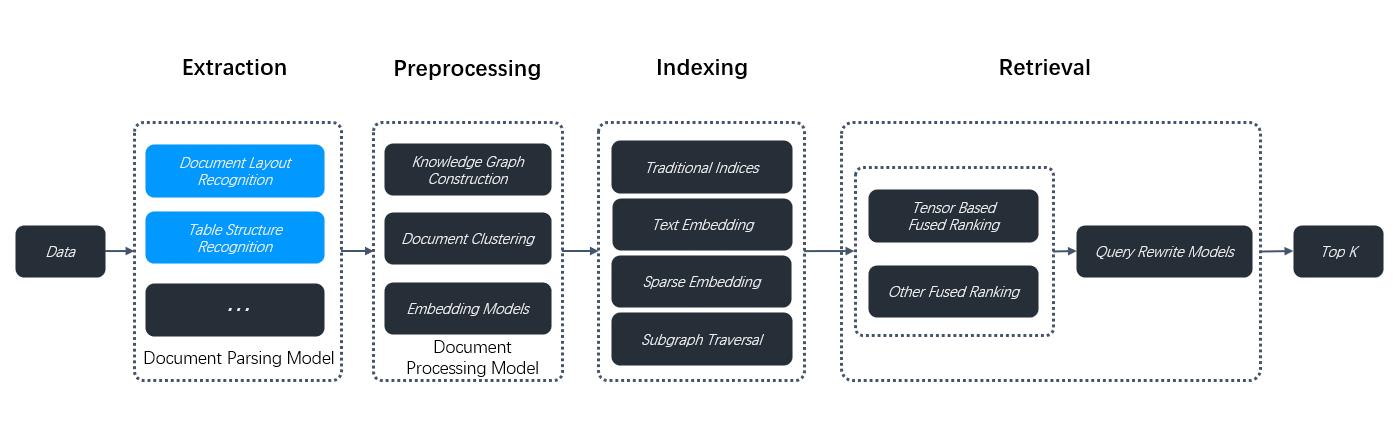
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- The PDF parser dropdown menu appears only when you select a chunking method compatible with PDFs, including:
|
||||
- **General**
|
||||
- **Manual**
|
||||
- **Paper**
|
||||
- **Book**
|
||||
- **Laws**
|
||||
- **Presentation**
|
||||
- **One**
|
||||
- To use a third-party visual model for parsing PDFs, ensure you have set a default image2txt model under **Set default models** on the **Model providers** page.
|
||||
|
||||
## Procedure
|
||||
|
||||
1. On your knowledge base's **Configuration** page, select a chunking method, say **General**.
|
||||
|
||||
_The **PDF parser** dropdown menu appears._
|
||||
|
||||
2. Select the option that works best with your scenario:
|
||||
|
||||
- DeepDoc: (Default) The default visual model for OCR, TSR, and DLR tasks.
|
||||
- Naive: Skip OCR, TSR, and DLR tasks if *all* your PDFs are plain text.
|
||||
- A third-party visual model provided by a specific model provider.
|
||||
|
||||
:::caution WARNING
|
||||
Third-party visual models are marked **Experimental**, because we have not fully tested these models for the aforementioned data extraction tasks.
|
||||
:::
|
||||
|
||||
## Frequently asked questions
|
||||
|
||||
### When should I select DeepDoc or a third-party visual model as the PDF parser?
|
||||
|
||||
Use a visual model to extract data if your PDFs contain formatted or image-based text rather than plain text. DeepDoc is the default visual model but can be time-consuming. You can also choose a lightweight or high-performance img2txt model depending on your needs and hardware capabilities.
|
||||
|
||||
### Can I select a visual model to parse my DOCX files?
|
||||
|
||||
No, you cannot. This dropdown menu is for PDFs only. To use this feature, convert your DOCX files to PDF first.
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
---
|
||||
sidebar_position: 1
|
||||
sidebar_position: 2
|
||||
slug: /set_metada
|
||||
---
|
||||
|
||||
|
||||
@ -144,7 +144,7 @@ export default {
|
||||
toMessage: 'Endseitennummer fehlt (ausgeschlossen)',
|
||||
layoutRecognize: 'Dokumentenparser',
|
||||
layoutRecognizeTip:
|
||||
'Verwendet ein visuelles Modell für die PDF-Layout-Analyse, um Dokumententitel, Textblöcke, Bilder und Tabellen effektiv zu lokalisieren. Wenn die einfache Option gewählt wird, wird nur der reine Text im PDF abgerufen. Bitte beachten Sie, dass diese Option derzeit NUR für PDF-Dokumente funktioniert.',
|
||||
'Verwendet ein visuelles Modell für die PDF-Layout-Analyse, um Dokumententitel, Textblöcke, Bilder und Tabellen effektiv zu lokalisieren. Wenn die einfache Option gewählt wird, wird nur der reine Text im PDF abgerufen. Bitte beachten Sie, dass diese Option derzeit NUR für PDF-Dokumente funktioniert. Weitere Informationen finden Sie unter https://ragflow.io/docs/dev/select_pdf_parser.',
|
||||
taskPageSize: 'Aufgabenseitengröße',
|
||||
taskPageSizeMessage: 'Bitte geben Sie die Größe der Aufgabenseite ein!',
|
||||
taskPageSizeTip:
|
||||
|
||||
@ -133,7 +133,7 @@ export default {
|
||||
toMessage: 'Falta el número de página final (excluido)',
|
||||
layoutRecognize: 'Reconocimiento de disposición',
|
||||
layoutRecognizeTip:
|
||||
'Usa modelos visuales para el análisis de disposición y así identificar mejor la estructura del documento, encontrar dónde están los títulos, bloques de texto, imágenes y tablas. Sin esta función, solo se obtendrá el texto plano del PDF.',
|
||||
'Usa modelos visuales para el análisis de disposición y así identificar mejor la estructura del documento, encontrar dónde están los títulos, bloques de texto, imágenes y tablas. Sin esta función, solo se obtendrá el texto plano del PDF. Para más información, consulte https://ragflow.io/docs/dev/select_pdf_parser.',
|
||||
taskPageSize: 'Tamaño de la tarea por página',
|
||||
taskPageSizeMessage:
|
||||
'¡Por favor ingresa el tamaño de la tarea por página!',
|
||||
|
||||
@ -138,7 +138,7 @@ export default {
|
||||
toMessage: 'Nomor halaman akhir hilang (tidak termasuk)',
|
||||
layoutRecognize: 'Pengenalan tata letak',
|
||||
layoutRecognizeTip:
|
||||
'Gunakan model visual untuk analisis tata letak untuk lebih mengidentifikasi struktur dokumen, menemukan di mana judul, blok teks, gambar, dan tabel berada. Tanpa fitur ini, hanya teks biasa dari PDF yang dapat diperoleh.',
|
||||
'Gunakan model visual untuk analisis tata letak untuk lebih mengidentifikasi struktur dokumen, menemukan di mana judul, blok teks, gambar, dan tabel berada. Tanpa fitur ini, hanya teks biasa dari PDF yang dapat diperoleh. Untuk informasi lebih lanjut, lihat https://ragflow.io/docs/dev/select_pdf_parser.',
|
||||
taskPageSize: 'Ukuran halaman tugas',
|
||||
taskPageSizeMessage: 'Silakan masukkan ukuran halaman tugas Anda!',
|
||||
taskPageSizeTip: `Jika menggunakan pengenalan tata letak, file PDF akan dibagi menjadi kelompok berturut-turut. Analisis tata letak akan dilakukan secara paralel antar kelompok untuk meningkatkan kecepatan pemrosesan. 'Ukuran halaman tugas' menentukan ukuran kelompok. Semakin besar ukuran halaman, semakin kecil kemungkinan teks berkelanjutan antara halaman dibagi menjadi potongan yang berbeda.`,
|
||||
|
||||
@ -138,7 +138,7 @@ export default {
|
||||
toMessage: '終了ページ番号が不足しています(除外)',
|
||||
layoutRecognize: 'レイアウト認識',
|
||||
layoutRecognizeTip:
|
||||
'レイアウト分析のためにビジュアルモデルを使用し、文書の構造を理解しやすくします。',
|
||||
'レイアウト分析のためにビジュアルモデルを使用し、文書の構造を理解しやすくします。詳細については、https://ragflow.io/docs/dev/select_pdf_parser をご覧ください。',
|
||||
taskPageSize: 'タスクページサイズ',
|
||||
taskPageSizeMessage: 'タスクページサイズを入力してください',
|
||||
taskPageSizeTip: `レイアウト認識中、PDFファイルはチャンクに分割され、処理速度を向上させるために並列処理されます。`,
|
||||
|
||||
@ -141,7 +141,7 @@ export default {
|
||||
toMessage: 'Página final ausente (excluída)',
|
||||
layoutRecognize: 'Reconhecimento de layout',
|
||||
layoutRecognizeTip:
|
||||
'Use modelos visuais para análise de layout para entender melhor a estrutura do documento e localizar efetivamente títulos, blocos de texto, imagens e tabelas. Se desativado, apenas o texto simples no PDF será recuperado.',
|
||||
'Use modelos visuais para análise de layout para entender melhor a estrutura do documento e localizar efetivamente títulos, blocos de texto, imagens e tabelas. Se desativado, apenas o texto simples no PDF será recuperado. Para mais informações, acesse https://ragflow.io/docs/dev/select_pdf_parser.',
|
||||
taskPageSize: 'Tamanho da página da tarefa',
|
||||
taskPageSizeMessage: 'Por favor, insira o tamanho da página da tarefa!',
|
||||
taskPageSizeTip:
|
||||
|
||||
@ -144,7 +144,7 @@ export default {
|
||||
toMessage: 'Thiếu số trang kết thúc (được loại trừ)',
|
||||
layoutRecognize: 'Nhận dạng bố cục',
|
||||
layoutRecognizeTip:
|
||||
'Sử dụng các mô hình trực quan để phân tích bố cục nhằm xác định tốt hơn cấu trúc tài liệu, tìm vị trí của tiêu đề, khối văn bản, hình ảnh và bảng. Nếu không có tính năng này, chỉ có thể lấy được văn bản thuần của PDF.',
|
||||
'Sử dụng các mô hình trực quan để phân tích bố cục nhằm xác định tốt hơn cấu trúc tài liệu, tìm vị trí của tiêu đề, khối văn bản, hình ảnh và bảng. Nếu không có tính năng này, chỉ có thể lấy được văn bản thuần của PDF. Để biết thêm thông tin, hãy xem https://ragflow.io/docs/dev/select_pdf_parser.',
|
||||
taskPageSize: 'Kích thước trang tác vụ',
|
||||
taskPageSizeMessage: 'Vui lòng nhập kích thước trang tác vụ của bạn!',
|
||||
taskPageSizeTip: `Nếu sử dụng nhận dạng bố cục, tệp PDF sẽ được chia thành các nhóm trang liên tiếp. Phân tích bố cục sẽ được thực hiện song song giữa các nhóm để tăng tốc độ xử lý. 'Kích thước trang tác vụ' xác định kích thước của các nhóm. Kích thước trang càng lớn, khả năng chia tách văn bản liên tục giữa các trang thành các khối khác nhau càng thấp.`,
|
||||
|
||||
@ -143,7 +143,7 @@ export default {
|
||||
toMessage: '缺少結束頁碼(不包含)',
|
||||
layoutRecognize: 'PDF解析器',
|
||||
layoutRecognizeTip:
|
||||
'使用視覺模型進行 PDF 布局分析,以更好地識別文檔結構,找到標題、文字塊、圖像和表格的位置。若選擇 Naive 選項,則只能取得 PDF 的純文字。請注意此功能僅適用於 PDF 文檔,對其他文檔不生效。',
|
||||
'使用視覺模型進行 PDF 布局分析,以更好地識別文檔結構,找到標題、文字塊、圖像和表格的位置。若選擇 Naive 選項,則只能取得 PDF 的純文字。請注意此功能僅適用於 PDF 文檔,對其他文檔不生效。如需更多資訊,請參閱 https://ragflow.io/docs/dev/select_pdf_parser。',
|
||||
taskPageSize: '任務頁面大小',
|
||||
taskPageSizeMessage: '請輸入您的任務頁面大小!',
|
||||
taskPageSizeTip: `如果使用佈局識別,PDF 文件將被分成連續的組。佈局分析將在組之間並行執行,以提高處理速度。“任務頁面大小”決定組的大小。頁面大小越大,將頁面之間的連續文本分割成不同塊的機會就越低。`,
|
||||
|
||||
@ -143,7 +143,7 @@ export default {
|
||||
toMessage: '缺少结束页码(不包含)',
|
||||
layoutRecognize: 'PDF解析器',
|
||||
layoutRecognizeTip:
|
||||
'使用视觉模型进行 PDF 布局分析,以更好地识别文档结构,找到标题、文本块、图像和表格的位置。 如果选择 Naive 选项,则只能获取 PDF 的纯文本。请注意该功能只适用于 PDF 文档,对其他文档不生效。',
|
||||
'使用视觉模型进行 PDF 布局分析,以更好地识别文档结构,找到标题、文本块、图像和表格的位置。 如果选择 Naive 选项,则只能获取 PDF 的纯文本。请注意该功能只适用于 PDF 文档,对其他文档不生效。欲了解更多信息,请参阅 https://ragflow.io/docs/dev/select_pdf_parser。',
|
||||
taskPageSize: '任务页面大小',
|
||||
taskPageSizeMessage: '请输入您的任务页面大小!',
|
||||
taskPageSizeTip: `如果使用布局识别,PDF 文件将被分成连续的组。 布局分析将在组之间并行执行,以提高处理速度。 “任务页面大小”决定组的大小。 页面大小越大,将页面之间的连续文本分割成不同块的机会就越低。`,
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user