mirror of
https://git.mirrors.martin98.com/https://github.com/infiniflow/ragflow.git
synced 2025-07-13 06:31:49 +08:00
Added a guide on setting chat variables (#6904)
### What problem does this PR solve? ### Type of change - [x] Documentation Update
This commit is contained in:
parent
aa99c6b896
commit
d0897312ac
23
docs/faq.mdx
23
docs/faq.mdx
@ -443,13 +443,26 @@ See [Upgrade RAGFlow](./guides/upgrade_ragflow.mdx) for more information.
|
||||
|
||||
To switch your document engine from Elasticsearch to [Infinity](https://github.com/infiniflow/infinity):
|
||||
|
||||
1. In **docker/.env**, set `DOC_ENGINE=${DOC_ENGINE:-infinity}`
|
||||
2. Restart your Docker image:
|
||||
1. Stop all running containers:
|
||||
|
||||
```bash
|
||||
$ docker compose -f docker-compose.yml up -d
|
||||
```
|
||||
```bash
|
||||
$ docker compose -f docker/docker-compose.yml down -v
|
||||
```
|
||||
:::caution WARNING
|
||||
`-v` will delete all Docker container volumes, and the existing data will be cleared.
|
||||
:::
|
||||
|
||||
2. In **docker/.env**, set `DOC_ENGINE=${DOC_ENGINE:-infinity}`
|
||||
3. Restart your Docker image:
|
||||
|
||||
```bash
|
||||
$ docker compose -f docker-compose.yml up -d
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### Where are my uploaded files stored in RAGFlow's image?
|
||||
|
||||
All uploaded files are stored in Minio, RAGFlow's object storage solution. For instance, if you upload your file directly to a knowledge base, it is located at `<knowledgebase_id>/filename`.
|
||||
|
||||
---
|
||||
@ -48,8 +48,8 @@ You can set global variables within the **Begin** component, which can be either
|
||||
|
||||
:::tip NOTE
|
||||
To pass in parameters from a client, call:
|
||||
- HTTP method [Converse with agent](../../references/http_api_reference.md#converse-with-agent), or
|
||||
- Python method [Converse with agent](../../referencespython_api_reference.md#converse-with-agent).
|
||||
- HTTP method [Converse with agent](../../../references/http_api_reference.md#converse-with-agent), or
|
||||
- Python method [Converse with agent](../../../referencespython_api_reference.md#converse-with-agent).
|
||||
:::
|
||||
|
||||
:::danger IMPORTANT
|
||||
|
||||
@ -20,7 +20,7 @@ Please note that some of your settings may consume a significant amount of time.
|
||||
Please note that rerank models are essential in certain scenarios. There is always a trade-off between speed and performance; you must weigh the pros against cons for your specific case.
|
||||
:::
|
||||
|
||||
- In the **Assistant Setting** tab of your **Chat Configuration** dialogue, disabling **Keyword analysis** will reduce the time to receive an answer from the LLM.
|
||||
- In the **Assistant settings** tab of your **Chat Configuration** dialogue, disabling **Keyword analysis** will reduce the time to receive an answer from the LLM.
|
||||
- When chatting with your chat assistant, click the light bulb icon above the *current* dialogue and scroll down the popup window to view the time taken for each task:
|
||||

|
||||
|
||||
|
||||
@ -15,11 +15,11 @@ From v0.17.0 onward, RAGFlow supports integrating agentic reasoning in an AI cha
|
||||
|
||||
To activate this feature:
|
||||
|
||||
1. Enable the **Reasoning** toggle under the **Prompt Engine** tab of your chat assistant dialogue.
|
||||
1. Enable the **Reasoning** toggle under the **Prompt engine** tab of your chat assistant dialogue.
|
||||
|
||||

|
||||
|
||||
2. Enter the correct Tavily API key under the **Assistant Setting** tab of your chat assistant dialogue to leverage Tavily-based web search
|
||||
2. Enter the correct Tavily API key under the **Assistant settings** tab of your chat assistant dialogue to leverage Tavily-based web search
|
||||
|
||||

|
||||
|
||||
|
||||
112
docs/guides/chat/set_chat_variables.md
Normal file
112
docs/guides/chat/set_chat_variables.md
Normal file
@ -0,0 +1,112 @@
|
||||
---
|
||||
sidebar_position: 4
|
||||
slug: /set_chat_variables
|
||||
---
|
||||
|
||||
# Set variables
|
||||
|
||||
Set variables to be used together with the system prompt for your LLM.
|
||||
|
||||
---
|
||||
|
||||
When configuring the system prompt for a chat model, variables play an important role in enhancing flexibility and reusability. With variables, you can dynamically adjust the system prompt to be sent to your model. In the context of RAGFlow, if you have defined variables in the **Chat Configuration** dialogue, except for the system's reserved variable `{knowledge}`, you are required to pass in values for them from RAGFlow's [HTTP API](../../references/http_api_reference.md#converse-with-chat-assistant) or through its [Python SDK](../../references/python_api_reference.md#converse-with-chat-assistant).
|
||||
|
||||
:::danger IMPORTANT
|
||||
In RAGFlow, variables are closely linked with the system prompt. When you add a variable in the **Variable** section, include it in the system prompt. Conversely, when deleting a variable, ensure it is removed from the system prompt; otherwise, an error would occur.
|
||||
:::
|
||||
|
||||
## Where to set variables
|
||||
|
||||
Hover your mouse over your chat assistant, click **Edit** to open its **Chat Configuration** dialogue, then click the **Prompt Engine** tab. Here, you can work on your variables in the **System prompt** field and the **Variable** section:
|
||||
|
||||
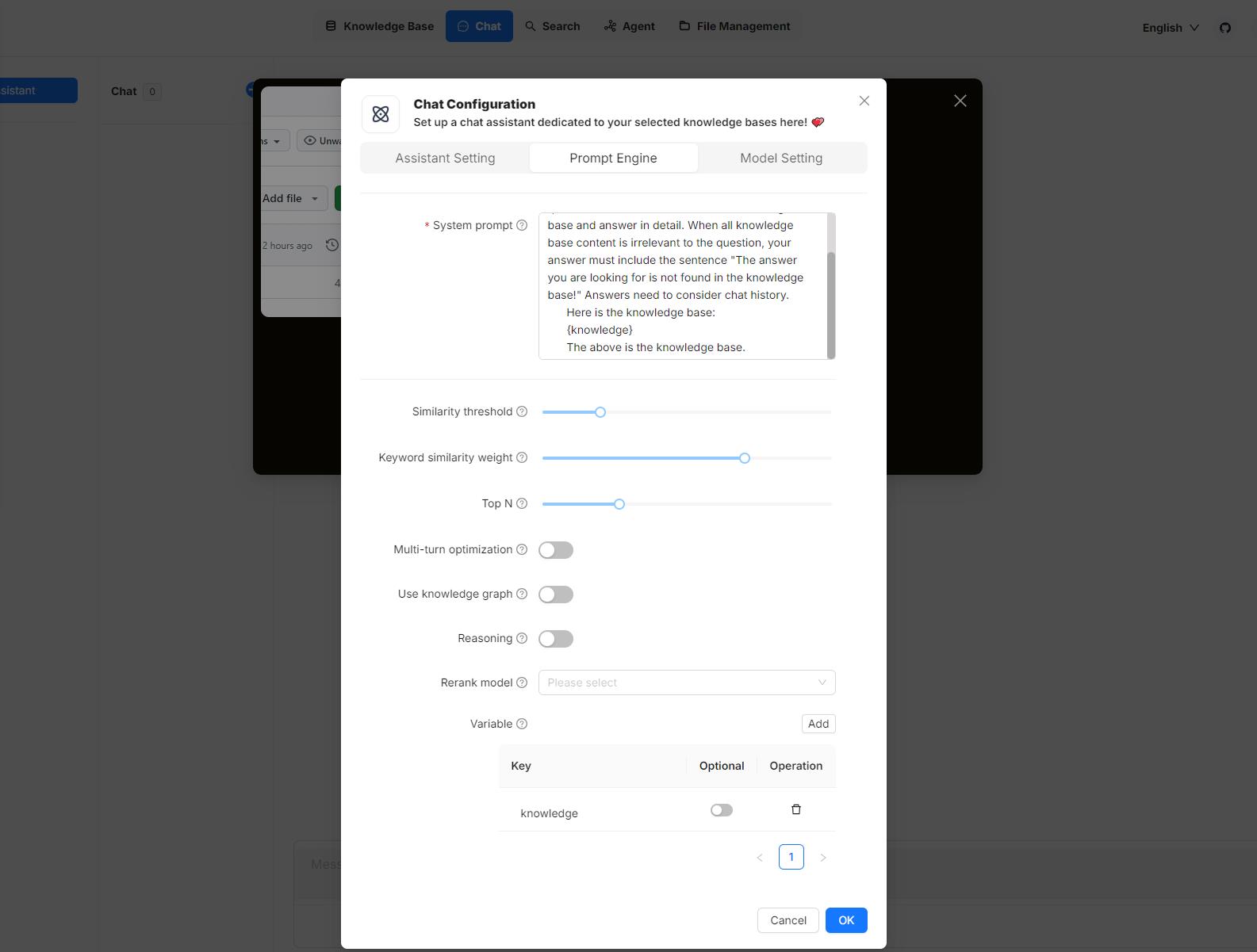
|
||||
|
||||
## 1. Manage variables
|
||||
|
||||
In the **Variable** section, you add, remove, or update variables.
|
||||
|
||||
### `{knowledge}` - a reserved variable
|
||||
|
||||
`{knowledge}` is the system's reserved variable, representing the chunks retrieved from the knowledge base(s) specified by **Knowledge bases** under the **Assistant settings** tab. If your chat assistant is associated with certain knowledge bases, you can keep it as is.
|
||||
|
||||
:::info NOTE
|
||||
It does not currently make a difference whether you set `{knowledge}` to optional or mandatory, but note that this design will be updated at a later point.
|
||||
:::
|
||||
|
||||
From v0.17.0 onward, you can start an AI chat without specifying knowledge bases. In this case, we recommend removing the `{knowledge}` variable to prevent unnecessary references and keeping the **Empty response** field empty to avoid errors.
|
||||
|
||||
### Custom variables
|
||||
|
||||
Besides `{knowledge}`, you can also define your own variables to pair with the system prompt. To use these custom variables, you must pass in their values through RAGFlow's official APIs. The **Optional** toggle determines whether these variables are required in the corresponding APIs:
|
||||
|
||||
- **Disabled** (Default): The variable is mandatory and must be provided.
|
||||
- **Enabled**: The variable is optional and can be omitted if not needed.
|
||||
|
||||
|
||||
|
||||
## 2. Update system prompt
|
||||
|
||||
After you add or remove variables in the **Variable** section, ensure your changes are reflected in the system prompt to avoid inconsistencies and errors. Here's an example:
|
||||
|
||||
```
|
||||
You are an intelligent assistant. Please answer the question by summarizing chunks from the specified knowledge base(s)...
|
||||
|
||||
Your answers should follow a professional and {style} style.
|
||||
|
||||
Here is the knowledge base:
|
||||
{knowledge}
|
||||
The above is the knowledge base.
|
||||
```
|
||||
|
||||
:::tip NOTE
|
||||
If you have removed `{knowledge}`, ensure that you thoroughly review and update the entire system prompt to achieve optimal results.
|
||||
:::
|
||||
|
||||
## APIs
|
||||
|
||||
The *only* way to pass in values for the custom variables defined in the **Chat Configuration** dialogue is to call RAGFlow's [HTTP API](../../references/http_api_reference.md#converse-with-chat-assistant) or through its [Python SDK](../../references/python_api_reference.md#converse-with-chat-assistant).
|
||||
|
||||
### HTTP API
|
||||
|
||||
See [Converse with chat assistant](../../references/http_api_reference.md#converse-with-chat-assistant). Here's an example:
|
||||
|
||||
```json {9}
|
||||
curl --request POST \
|
||||
--url http://{address}/api/v1/chats/{chat_id}/completions \
|
||||
--header 'Content-Type: application/json' \
|
||||
--header 'Authorization: Bearer <YOUR_API_KEY>' \
|
||||
--data-binary '
|
||||
{
|
||||
"question": "xxxxxxxxx",
|
||||
"stream": true,
|
||||
"style":"hilarious"
|
||||
}'
|
||||
```
|
||||
|
||||
### Python API
|
||||
|
||||
See [Converse with chat assistant](../../references/python_api_reference.md#converse-with-chat-assistant). Here's an example:
|
||||
|
||||
```python {18}
|
||||
from ragflow_sdk import RAGFlow
|
||||
|
||||
rag_object = RAGFlow(api_key="<YOUR_API_KEY>", base_url="http://<YOUR_BASE_URL>:9380")
|
||||
assistant = rag_object.list_chats(name="Miss R")
|
||||
assistant = assistant[0]
|
||||
session = assistant.create_session()
|
||||
|
||||
print("\n==================== Miss R =====================\n")
|
||||
print("Hello. What can I do for you?")
|
||||
|
||||
while True:
|
||||
question = input("\n==================== User =====================\n> ")
|
||||
style = input("Please enter your preferred style (e.g., formal, informal, hilarious): ")
|
||||
|
||||
print("\n==================== Miss R =====================\n")
|
||||
|
||||
cont = ""
|
||||
for ans in session.ask(question, stream=True, style=style):
|
||||
print(ans.content[len(cont):], end='', flush=True)
|
||||
cont = ans.content
|
||||
```
|
||||
|
||||
@ -19,7 +19,7 @@ You start an AI conversation by creating an assistant.
|
||||
|
||||
> RAGFlow offers you the flexibility of choosing a different chat model for each dialogue, while allowing you to set the default models in **System Model Settings**.
|
||||
|
||||
2. Update **Assistant Setting**:
|
||||
2. Update **Assistant Settings**:
|
||||
|
||||
- **Assistant name** is the name of your chat assistant. Each assistant corresponds to a dialogue with a unique combination of knowledge bases, prompts, hybrid search configurations, and large model settings.
|
||||
- **Empty response**:
|
||||
|
||||
@ -70,7 +70,7 @@ In a knowledge graph, a community is a cluster of entities linked by relationshi
|
||||
3. Click **Knowledge graph** to view the details of the generated graph.
|
||||
4. To use the created knowledge graph, do either of the following:
|
||||
|
||||
- In your **Chat Configuration** dialogue, click the **Assistant Setting** tab to add the corresponding knowledge base(s) and click the **Prompt Engine** tab to switch on the **Use knowledge graph** toggle.
|
||||
- In your **Chat Configuration** dialogue, click the **Assistant settings** tab to add the corresponding knowledge base(s) and click the **Prompt engine** tab to switch on the **Use knowledge graph** toggle.
|
||||
- If you are using an agent, click the **Retrieval** agent component to specify the knowledge base(s) and switch on the **Use knowledge graph** toggle.
|
||||
|
||||
## Frequently asked questions
|
||||
|
||||
@ -11,7 +11,7 @@ Use a tag set to tag chunks in your datasets.
|
||||
|
||||
Retrieval accuracy is the touchstone for a production-ready RAG framework. In addition to retrieval-enhancing approaches like auto-keyword, auto-question, and knowledge graph, RAGFlow introduces an auto-tagging feature to address semantic gaps. The auto-tagging feature automatically maps tags in the user-defined tag sets to relevant chunks within your knowledge base based on similarity with each chunk. This automation mechanism allows you to apply an additional "layer" of domain-specific knowledge to existing datasets, which is particularly useful when dealing with a large number of chunks.
|
||||
|
||||
To use this feature, ensure you have at least one properly configured tag set, specify the tag set(s) on the **Configuration** page of your knowledge base (dataset), and then re-parse your documents to initiate the auto-tag process. During this process, each chunk in your dataset is compared with every entry in the specified tag set(s), and tags are automatically applied based on similarity.
|
||||
To use this feature, ensure you have at least one properly configured tag set, specify the tag set(s) on the **Configuration** page of your knowledge base (dataset), and then re-parse your documents to initiate the auto-tagging process. During this process, each chunk in your dataset is compared with every entry in the specified tag set(s), and tags are automatically applied based on similarity.
|
||||
|
||||
:::caution NOTE
|
||||
The auto-tagging feature is *unavailable* on the [Infinity](https://github.com/infiniflow/infinity) document engine.
|
||||
@ -19,7 +19,7 @@ The auto-tagging feature is *unavailable* on the [Infinity](https://github.com/i
|
||||
|
||||
## Scenarios
|
||||
|
||||
Auto-tagging applies in situations where chunks are so similar to each other that the intended chunks cannot be distinguished from the rest. For example, when you have a few chunks about iPhone and a majority about iPhone case or iPhone accessaries, it becomes difficult to retrieve the iPhone-specific chunks without additional information.
|
||||
Auto-tagging applies in situations where chunks are so similar to each other that the intended chunks cannot be distinguished from the rest. For example, when you have a few chunks about iPhone and a majority about iPhone case or iPhone accessaries, it becomes difficult to retrieve those chunks about iPhone without additional information.
|
||||
|
||||
## Create tag set
|
||||
|
||||
|
||||
@ -7,7 +7,7 @@ slug: /manage_files
|
||||
|
||||
Knowledge base, hallucination-free chat, and file management are the three pillars of RAGFlow. RAGFlow's file management allows you to upload files individually or in bulk. You can then link an uploaded file to multiple target knowledge bases. This guide showcases some basic usages of the file management feature.
|
||||
|
||||
:::danger IMPORTANT
|
||||
:::info IMPORTANT
|
||||
Compared to uploading files directly to various knowledge bases, uploading them to RAGFlow's file management and then linking them to different knowledge bases is *not* an unnecessary step, particularly when you want to delete some parsed files or an entire knowledge base but retain the original files.
|
||||
:::
|
||||
|
||||
@ -17,7 +17,9 @@ RAGFlow's file management allows you to establish your file system with nested f
|
||||
|
||||

|
||||
|
||||
> Each knowledge base in RAGFlow has a corresponding folder under the **root/.knowledgebase** directory. You are not allowed to create a subfolder within it.
|
||||
:::caution NOTE
|
||||
Each knowledge base in RAGFlow has a corresponding folder under the **root/.knowledgebase** directory. You are not allowed to create a subfolder within it.
|
||||
:::
|
||||
|
||||
## Upload file
|
||||
|
||||
|
||||
@ -39,4 +39,4 @@ _After accepting the team invite, you should be able to view and update the team
|
||||
|
||||
## Leave a joined team
|
||||
|
||||

|
||||
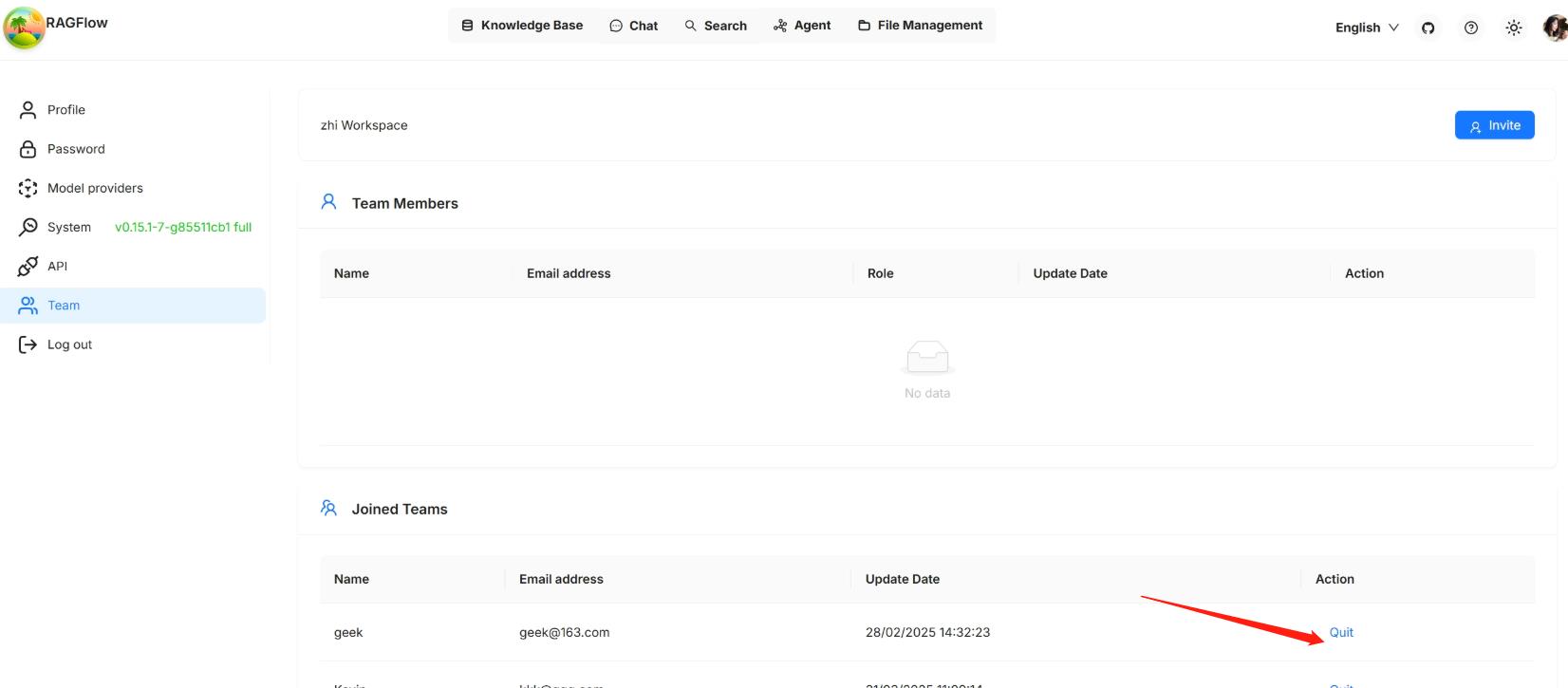
|
||||
@ -302,7 +302,7 @@ Once you have selected an embedding model and used it to parse a file, you are n
|
||||
_When the file parsing completes, its parsing status changes to **SUCCESS**._
|
||||
|
||||
:::caution NOTE
|
||||
- If your file parsing gets stuck at below 1%, see [this FAQ](./faq.mdxfaq#why-does-my-document-parsing-stall-at-under-one-percent).
|
||||
- If your file parsing gets stuck at below 1%, see [this FAQ](./faq.mdx#why-does-my-document-parsing-stall-at-under-one-percent).
|
||||
- If your file parsing gets stuck at near completion, see [this FAQ](./faq.mdx#why-does-my-pdf-parsing-stall-near-completion-while-the-log-does-not-show-any-error)
|
||||
:::
|
||||
|
||||
@ -339,16 +339,16 @@ Conversations in RAGFlow are based on a particular knowledge base or multiple kn
|
||||
1. Click the **Chat** tab in the middle top of the mage **>** **Create an assistant** to show the **Chat Configuration** dialogue *of your next dialogue*.
|
||||
> RAGFlow offer the flexibility of choosing a different chat model for each dialogue, while allowing you to set the default models in **System Model Settings**.
|
||||
|
||||
2. Update **Assistant Setting**:
|
||||
2. Update **Assistant settings**:
|
||||
|
||||
- Name your assistant and specify your knowledge bases.
|
||||
- **Empty response**:
|
||||
- If you wish to *confine* RAGFlow's answers to your knowledge bases, leave a response here. Then when it doesn't retrieve an answer, it *uniformly* responds with what you set here.
|
||||
- If you wish RAGFlow to *improvise* when it doesn't retrieve an answer from your knowledge bases, leave it blank, which may give rise to hallucinations.
|
||||
|
||||
3. Update **Prompt Engine** or leave it as is for the beginning.
|
||||
3. Update **Prompt engine** or leave it as is for the beginning.
|
||||
|
||||
4. Update **Model Setting**.
|
||||
4. Update **Model settings**.
|
||||
|
||||
5. Now, let's start the show:
|
||||
|
||||
|
||||
@ -403,7 +403,7 @@ curl --request POST \
|
||||
- `"chunk_token_count"`: Defaults to `128`.
|
||||
- `"layout_recognize"`: Defaults to `true`.
|
||||
- `"html4excel"`: Indicates whether to convert Excel documents into HTML format. Defaults to `false`.
|
||||
- `"delimiter"`: Defaults to `"\n!?。;!?"`.
|
||||
- `"delimiter"`: Defaults to `"\n"`.
|
||||
- `"task_page_size"`: Defaults to `12`. For PDF only.
|
||||
- `"raptor"`: Raptor-specific settings. Defaults to: `{"use_raptor": false}`.
|
||||
- If `"chunk_method"` is `"qa"`, `"manuel"`, `"paper"`, `"book"`, `"laws"`, or `"presentation"`, the `"parser_config"` object contains the following attribute:
|
||||
@ -411,7 +411,7 @@ curl --request POST \
|
||||
- If `"chunk_method"` is `"table"`, `"picture"`, `"one"`, or `"email"`, `"parser_config"` is an empty JSON object.
|
||||
- If `"chunk_method"` is `"knowledge_graph"`, the `"parser_config"` object contains the following attributes:
|
||||
- `"chunk_token_count"`: Defaults to `128`.
|
||||
- `"delimiter"`: Defaults to `"\n!?。;!?"`.
|
||||
- `"delimiter"`: Defaults to `"\n"`.
|
||||
- `"entity_types"`: Defaults to `["organization","person","location","event","time"]`
|
||||
|
||||
#### Response
|
||||
@ -436,7 +436,7 @@ Success:
|
||||
"name": "test_1",
|
||||
"parser_config": {
|
||||
"chunk_token_num": 128,
|
||||
"delimiter": "\\n!?;。;!?",
|
||||
"delimiter": "\\n",
|
||||
"html4excel": false,
|
||||
"layout_recognize": true,
|
||||
"raptor": {
|
||||
@ -658,7 +658,7 @@ Success:
|
||||
"chunk_method": "knowledge_graph",
|
||||
"parser_config": {
|
||||
"chunk_token_num": 8192,
|
||||
"delimiter": "\\n!?;。;!?",
|
||||
"delimiter": "\\n",
|
||||
"entity_types": [
|
||||
"organization",
|
||||
"person",
|
||||
@ -746,7 +746,7 @@ Success:
|
||||
"name": "1.txt",
|
||||
"parser_config": {
|
||||
"chunk_token_num": 128,
|
||||
"delimiter": "\\n!?;。;!?",
|
||||
"delimiter": "\\n",
|
||||
"html4excel": false,
|
||||
"layout_recognize": true,
|
||||
"raptor": {
|
||||
@ -835,7 +835,7 @@ curl --request PUT \
|
||||
- `"chunk_token_count"`: Defaults to `128`.
|
||||
- `"layout_recognize"`: Defaults to `true`.
|
||||
- `"html4excel"`: Indicates whether to convert Excel documents into HTML format. Defaults to `false`.
|
||||
- `"delimiter"`: Defaults to `"\n!?。;!?"`.
|
||||
- `"delimiter"`: Defaults to `"\n"`.
|
||||
- `"task_page_size"`: Defaults to `12`. For PDF only.
|
||||
- `"raptor"`: Raptor-specific settings. Defaults to: `{"use_raptor": false}`.
|
||||
- If `"chunk_method"` is `"qa"`, `"manuel"`, `"paper"`, `"book"`, `"laws"`, or `"presentation"`, the `"parser_config"` object contains the following attribute:
|
||||
@ -843,7 +843,7 @@ curl --request PUT \
|
||||
- If `"chunk_method"` is `"table"`, `"picture"`, `"one"`, or `"email"`, `"parser_config"` is an empty JSON object.
|
||||
- If `"chunk_method"` is `"knowledge_graph"`, the `"parser_config"` object contains the following attributes:
|
||||
- `"chunk_token_count"`: Defaults to `128`.
|
||||
- `"delimiter"`: Defaults to `"\n!?。;!?"`.
|
||||
- `"delimiter"`: Defaults to `"\n"`.
|
||||
- `"entity_types"`: Defaults to `["organization","person","location","event","time"]`
|
||||
|
||||
#### Response
|
||||
@ -978,7 +978,7 @@ Success:
|
||||
"name": "Test_2.txt",
|
||||
"parser_config": {
|
||||
"chunk_token_count": 128,
|
||||
"delimiter": "\n!?。;!?",
|
||||
"delimiter": "\n",
|
||||
"layout_recognize": true,
|
||||
"task_page_size": 12
|
||||
},
|
||||
@ -1335,7 +1335,7 @@ Success:
|
||||
"name": "1.txt",
|
||||
"parser_config": {
|
||||
"chunk_token_num": 128,
|
||||
"delimiter": "\\n!?;。;!?",
|
||||
"delimiter": "\\n",
|
||||
"html4excel": false,
|
||||
"layout_recognize": true,
|
||||
"raptor": {
|
||||
|
||||
@ -154,7 +154,7 @@ The chunking method of the dataset to create. Available options:
|
||||
The parser configuration of the dataset. A `ParserConfig` object's attributes vary based on the selected `chunk_method`:
|
||||
|
||||
- `chunk_method`=`"naive"`:
|
||||
`{"chunk_token_num":128,"delimiter":"\\n!?;。;!?","html4excel":False,"layout_recognize":True,"raptor":{"user_raptor":False}}`.
|
||||
`{"chunk_token_num":128,"delimiter":"\\n","html4excel":False,"layout_recognize":True,"raptor":{"user_raptor":False}}`.
|
||||
- `chunk_method`=`"qa"`:
|
||||
`{"raptor": {"user_raptor": False}}`
|
||||
- `chunk_method`=`"manuel"`:
|
||||
@ -174,7 +174,7 @@ The parser configuration of the dataset. A `ParserConfig` object's attributes va
|
||||
- `chunk_method`=`"one"`:
|
||||
`None`
|
||||
- `chunk_method`=`"knowledge-graph"`:
|
||||
`{"chunk_token_num":128,"delimiter":"\\n!?;。;!?","entity_types":["organization","person","location","event","time"]}`
|
||||
`{"chunk_token_num":128,"delimiter":"\\n","entity_types":["organization","person","location","event","time"]}`
|
||||
- `chunk_method`=`"email"`:
|
||||
`None`
|
||||
|
||||
@ -403,7 +403,7 @@ A dictionary representing the attributes to update, with the following keys:
|
||||
- `"email"`: Email
|
||||
- `"parser_config"`: `dict[str, Any]` The parsing configuration for the document. Its attributes vary based on the selected `"chunk_method"`:
|
||||
- `"chunk_method"`=`"naive"`:
|
||||
`{"chunk_token_num":128,"delimiter":"\\n!?;。;!?","html4excel":False,"layout_recognize":True,"raptor":{"user_raptor":False}}`.
|
||||
`{"chunk_token_num":128,"delimiter":"\\n","html4excel":False,"layout_recognize":True,"raptor":{"user_raptor":False}}`.
|
||||
- `chunk_method`=`"qa"`:
|
||||
`{"raptor": {"user_raptor": False}}`
|
||||
- `chunk_method`=`"manuel"`:
|
||||
@ -423,7 +423,7 @@ A dictionary representing the attributes to update, with the following keys:
|
||||
- `chunk_method`=`"one"`:
|
||||
`None`
|
||||
- `chunk_method`=`"knowledge-graph"`:
|
||||
`{"chunk_token_num":128,"delimiter":"\\n!?;。;!?","entity_types":["organization","person","location","event","time"]}`
|
||||
`{"chunk_token_num":128,"delimiter":"\\n","entity_types":["organization","person","location","event","time"]}`
|
||||
- `chunk_method`=`"email"`:
|
||||
`None`
|
||||
|
||||
@ -543,7 +543,7 @@ A `Document` object contains the following attributes:
|
||||
- `status`: `str` Reserved for future use.
|
||||
- `parser_config`: `ParserConfig` Configuration object for the parser. Its attributes vary based on the selected `chunk_method`:
|
||||
- `chunk_method`=`"naive"`:
|
||||
`{"chunk_token_num":128,"delimiter":"\\n!?;。;!?","html4excel":False,"layout_recognize":True,"raptor":{"user_raptor":False}}`.
|
||||
`{"chunk_token_num":128,"delimiter":"\\n","html4excel":False,"layout_recognize":True,"raptor":{"user_raptor":False}}`.
|
||||
- `chunk_method`=`"qa"`:
|
||||
`{"raptor": {"user_raptor": False}}`
|
||||
- `chunk_method`=`"manuel"`:
|
||||
@ -563,7 +563,7 @@ A `Document` object contains the following attributes:
|
||||
- `chunk_method`=`"one"`:
|
||||
`None`
|
||||
- `chunk_method`=`"knowledge-graph"`:
|
||||
`{"chunk_token_num":128,"delimiter": "\\n!?;。;!?","entity_types":["organization","person","location","event","time"]}`
|
||||
`{"chunk_token_num":128,"delimiter": "\\n","entity_types":["organization","person","location","event","time"]}`
|
||||
- `chunk_method`=`"email"`:
|
||||
`None`
|
||||
|
||||
|
||||
@ -75,7 +75,7 @@ Released on March 3, 2025.
|
||||
### New features
|
||||
|
||||
- AI chat: Implements Deep Research for agentic reasoning. To activate this, enable the **Reasoning** toggle under the **Prompt Engine** tab of your chat assistant dialogue.
|
||||
- AI chat: Leverages Tavily-based web search to enhance contexts in agentic reasoning. To activate this, enter the correct Tavily API key under the **Assistant Setting** tab of your chat assistant dialogue.
|
||||
- AI chat: Leverages Tavily-based web search to enhance contexts in agentic reasoning. To activate this, enter the correct Tavily API key under the **Assistant settings** tab of your chat assistant dialogue.
|
||||
- AI chat: Supports starting a chat without specifying knowledge bases.
|
||||
- AI chat: HTML files can also be previewed and referenced, in addition to PDF files.
|
||||
- Dataset: Adds a **PDF parser**, aka **Document parser**, dropdown menu to dataset configurations. This includes a DeepDoc model option, which is time-consuming, a much faster **naive** option (plain text), which skips DLA (Document Layout Analysis), OCR (Optical Character Recognition), and TSR (Table Structure Recognition) tasks, and several currently *experimental* large model options.
|
||||
|
||||
@ -164,7 +164,7 @@ export default {
|
||||
rerankTip:
|
||||
'Wenn leer gelassen, verwendet RAGFlow eine Kombination aus gewichteter Schlüsselwortähnlichkeit und gewichteter Vektorkosinus-Ähnlichkeit; wenn ein Neuordnungsmodell ausgewählt wird, ersetzt eine gewichtete Neuordnungsbewertung die gewichtete Vektorkosinus-Ähnlichkeit. Bitte beachten Sie, dass die Verwendung eines Neuordnungsmodells die Antwortzeit des Systems erheblich erhöht.',
|
||||
topK: 'Top-K',
|
||||
topKTip: 'K Chunks werden in das Neuordnungsmodell eingespeist.',
|
||||
topKTip: 'In Verbindung mit dem Rerank model wird mit dieser Einstellung die Anzahl der Textblöcke festgelegt, die an das angegebene reranking model gesendet werden.',
|
||||
delimiter: 'Trennzeichen für Textsegmentierung',
|
||||
delimiterTip:
|
||||
'Ein Trennzeichen oder Separator kann aus einem oder mehreren Sonderzeichen bestehen. Bei mehreren Zeichen stellen Sie sicher, dass sie in Backticks (` `) eingeschlossen sind. Wenn Sie beispielsweise Ihre Trennzeichen so konfigurieren: \\n`##`;, dann werden Ihre Texte an Zeilenumbrüchen, doppelten Rautenzeichen (##) oder Semikolons getrennt. Setzen Sie Trennzeichen nur nachdem Sie das Mechanismus der Textsegmentierung und -chunking verstanden haben.',
|
||||
@ -424,7 +424,7 @@ export default {
|
||||
sendPlaceholder: 'Nachricht an den Assistenten...',
|
||||
chatConfiguration: 'Chat-Konfiguration',
|
||||
chatConfigurationDescription:
|
||||
'Richten Sie hier einen Chat-Assistenten ein, der für Ihre ausgewählten Wissensdatenbanken dediziert ist! 💕',
|
||||
'Richten Sie einen Chat-Assistenten für die ausgewählten Datensätze (Wissensbasen) hier ein! 💕',
|
||||
assistantName: 'Assistentenname',
|
||||
assistantNameMessage: 'Assistentenname ist erforderlich',
|
||||
namePlaceholder: 'z.B. Lebenslauf-Jarvis',
|
||||
@ -454,7 +454,7 @@ export default {
|
||||
'Nicht alle Chunks mit einem Ähnlichkeitswert über dem "Ähnlichkeitsschwellenwert" werden an das LLM gesendet. Dies wählt die "Top N" Chunks aus den abgerufenen aus.',
|
||||
variable: 'Variable',
|
||||
variableTip:
|
||||
'Variablen können bei der Entwicklung flexiblerer Strategien helfen, insbesondere wenn Sie unsere Chat-Assistenten-Management-APIs verwenden. Diese Variablen werden von "System" als Teil der Prompts für das LLM verwendet. Die Variable {knowledge} ist eine reservierte spezielle Variable, die Ihre ausgewählte(n) Wissensdatenbank(en) repräsentiert, und alle Variablen sollten in geschweifte Klammern {} eingeschlossen sein.',
|
||||
'In Kombination mit den APIs zur Verwaltung von Chat-Assistenten von RAGFlow können Variablen dazu beitragen, flexiblere System-Prompt-Strategien zu entwickeln. Die definierten Variablen werden von „System-Prompt“ als Teil der Prompts für das LLM verwendet. {knowledge} ist eine spezielle reservierte Variable, die Teile darstellt, die aus den angegebenen Wissensbasen abgerufen werden, und alle Variablen sollten in geschweiften Klammern {} im „System-Prompt“ eingeschlossen werden. Weitere Informationen finden Sie unter https://ragflow.io/docs/dev/set_chat_variables.',
|
||||
add: 'Hinzufügen',
|
||||
key: 'Schlüssel',
|
||||
optional: 'Optional',
|
||||
|
||||
@ -161,7 +161,7 @@ export default {
|
||||
rerankPlaceholder: 'Please select',
|
||||
rerankTip: `If left empty, RAGFlow will use a combination of weighted keyword similarity and weighted vector cosine similarity; if a rerank model is selected, a weighted reranking score will replace the weighted vector cosine similarity. Please be aware that using a rerank model will significantly increase the system's response time.`,
|
||||
topK: 'Top-K',
|
||||
topKTip: `K chunks will be sent into the rerank model.`,
|
||||
topKTip: `Used together with the Rerank model, this setting defines the number of text chunks to be sent to the specified reranking model.`,
|
||||
delimiter: `Delimiter for text`,
|
||||
delimiterTip:
|
||||
'A delimiter or separator can consist of one or multiple special characters. If it is multiple characters, ensure they are enclosed in backticks( ``). For example, if you configure your delimiters like this: \\n`##`;, then your texts will be separated at line breaks, double hash symbols (##), and semicolons.',
|
||||
@ -404,7 +404,7 @@ This auto-tagging feature enhances retrieval by adding another layer of domain-s
|
||||
chat: {
|
||||
newConversation: 'New conversation',
|
||||
createAssistant: 'Create an Assistant',
|
||||
assistantSetting: 'Assistant Setting',
|
||||
assistantSetting: 'Assistant settings',
|
||||
promptEngine: 'Prompt Engine',
|
||||
modelSetting: 'Model Setting',
|
||||
chat: 'Chat',
|
||||
@ -413,7 +413,7 @@ This auto-tagging feature enhances retrieval by adding another layer of domain-s
|
||||
sendPlaceholder: 'Message the assistant...',
|
||||
chatConfiguration: 'Chat Configuration',
|
||||
chatConfigurationDescription:
|
||||
' Set up a chat assistant dedicated to your selected knowledge bases here! 💕',
|
||||
' Set up a chat assistant for your selected datasets (knowledge bases) here! 💕',
|
||||
assistantName: 'Assistant name',
|
||||
assistantNameMessage: 'Assistant name is required',
|
||||
namePlaceholder: 'e.g. Resume Jarvis',
|
||||
@ -440,7 +440,7 @@ This auto-tagging feature enhances retrieval by adding another layer of domain-s
|
||||
topN: 'Top N',
|
||||
topNTip: `Not all chunks with similarity score above the 'similarity threshold' will be sent to the LLM. This selects 'Top N' chunks from the retrieved ones.`,
|
||||
variable: 'Variable',
|
||||
variableTip: `Variables can assist in developing more flexible strategies, particularly when you are using our chat assistant management APIs. These variables will be used by 'System prompt' as part of the prompts for the LLM. The variable {knowledge} is a reserved special variable representing your selected knowledge base(s), and all variables should be enclosed in curly braces {}.`,
|
||||
variableTip: `Used together with RAGFlow's chat assistant management APIs, variables can help develop more flexible system prompt strategies. The defined variables will be used by 'System prompt' as part of the prompts for the LLM. {knowledge} is a reserved special variable representing chunks retrieved from specified knowledge base(s), and all variables should be enclosed in curly braces {} in the 'System prompt'. See https://ragflow.io/docs/dev/set_chat_variables for details.`,
|
||||
add: 'Add',
|
||||
key: 'Key',
|
||||
optional: 'Optional',
|
||||
|
||||
@ -151,7 +151,7 @@ export default {
|
||||
rerankPlaceholder: 'Por favor selecciona',
|
||||
rerankTip: `Si está vacío, se utilizan los embeddings de la consulta y los fragmentos para calcular la similitud coseno del vector. De lo contrario, se usa la puntuación de reordenamiento en lugar de la similitud coseno del vector.`,
|
||||
topK: 'Top-K',
|
||||
topKTip: `K fragmentos serán alimentados a los modelos de reordenamiento.`,
|
||||
topKTip: `Utilizado junto con el Rerank model, esta configuración define el número de fragmentos de texto que se enviarán al modelo reranking especificado.`,
|
||||
delimiter: `Delimitadores para segmentación de texto`,
|
||||
html4excel: 'Excel a HTML',
|
||||
html4excelTip: `Usar junto con el método de fragmentación General. Cuando está desactivado, los archivos de hoja de cálculo (XLSX, XLS (Excel97~2003)) se analizan línea por línea como pares clave-valor. Cuando está activado, los archivos de hoja de cálculo se convierten en tablas HTML. Si la tabla original tiene más de 12 filas, el sistema la dividirá automáticamente en varias tablas HTML cada 12 filas.`,
|
||||
@ -171,7 +171,7 @@ export default {
|
||||
sendPlaceholder: 'Enviar mensaje al Asistente...',
|
||||
chatConfiguration: 'Configuración del Chat',
|
||||
chatConfigurationDescription:
|
||||
'Aquí, personaliza un asistente dedicado para tus bases de conocimiento especiales 💕',
|
||||
'Configura un asistente de chat para los conjuntos de datos seleccionados (bases de conocimiento) aquí. 💕',
|
||||
assistantName: 'Nombre del asistente',
|
||||
assistantNameMessage: 'El nombre del asistente es obligatorio',
|
||||
namePlaceholder: 'p.ej. Resume Jarvis',
|
||||
@ -196,10 +196,7 @@ export default {
|
||||
topN: 'Top N',
|
||||
topNTip: `No todos los fragmentos cuya puntuación de similitud esté por encima del "umbral de similitud" serán enviados a los LLMs. Los LLMs solo pueden ver estos "Top N" fragmentos.`,
|
||||
variable: 'Variable',
|
||||
variableTip: `Si usas APIs de diálogo, las variables pueden ayudarte a chatear con tus clientes usando diferentes estrategias.
|
||||
Las variables se utilizan para completar la parte "prompt del sistema" del prompt para darle una pista al LLM.
|
||||
La "base de conocimiento" es una variable muy especial que se completará con los fragmentos recuperados.
|
||||
Todas las variables en "prompt del sistema" deben estar entre llaves.`,
|
||||
variableTip: `Usados junto con las API de gestión de asistentes de chat de RAGFlow, las variables pueden ayudar a desarrollar estrategias de prompt del sistema más flexibles. Las variables definidas serán utilizadas por el 'Prompt del sistema' como parte de los prompts para el LLM. {knowledge} es una variable especial reservada que representa partes recuperadas de base(s) de conocimiento especificada(s), y todas las variables deben estar rodeadas por llaves {} en el 'Prompt del sistema'. Consulte https://ragflow.io/docs/dev/set_chat_variables para obtener más detalles.`,
|
||||
add: 'Agregar',
|
||||
key: 'Clave',
|
||||
optional: 'Opcional',
|
||||
|
||||
@ -155,7 +155,7 @@ export default {
|
||||
rerankPlaceholder: 'Silakan pilih',
|
||||
rerankTip: `Jika kosong. Ini menggunakan embedding dari kueri dan potongan untuk menghitung kesamaan kosinus vektor. Jika tidak, ini menggunakan skor rerank sebagai pengganti kesamaan kosinus vektor.`,
|
||||
topK: 'Top-K',
|
||||
topKTip: `K potongan akan dimasukkan ke dalam model rerank.`,
|
||||
topKTip: `Digunakan bersama dengan Rerank model, pengaturan ini menentukan jumlah potongan teks yang akan dikirim ke model reranking yang ditentukan.`,
|
||||
delimiter: `Pemisah untuk segmentasi teks`,
|
||||
html4excel: 'Excel ke HTML',
|
||||
html4excelTip: `Gunakan bersama dengan metode pemotongan General. Ketika dinonaktifkan, file spreadsheet (XLSX, XLS (Excel97~2003)) akan dianalisis baris demi baris menjadi pasangan kunci-nilai. Ketika diaktifkan, file spreadsheet akan dianalisis menjadi tabel HTML. Jika tabel asli memiliki lebih dari 12 baris, sistem akan secara otomatis membagi menjadi beberapa tabel HTML setiap 12 baris.`,
|
||||
@ -342,7 +342,7 @@ export default {
|
||||
sendPlaceholder: 'Pesan ke Asisten...',
|
||||
chatConfiguration: 'Konfigurasi Obrolan',
|
||||
chatConfigurationDescription:
|
||||
'Di sini, dandani asisten khusus untuk basis pengetahuan khusus Anda! 💕',
|
||||
'Atur asisten obrolan untuk dataset yang dipilih (basis pengetahuan) di sini. 💕',
|
||||
assistantName: 'Nama Asisten',
|
||||
assistantNameMessage: 'Nama asisten diperlukan',
|
||||
namePlaceholder: 'mis. Resume Jarvis',
|
||||
@ -367,10 +367,7 @@ export default {
|
||||
topN: 'Top N',
|
||||
topNTip: `Tidak semua potongan yang skor kesamaannya di atas 'ambang kesamaan' akan diberikan ke LLM. LLM hanya dapat melihat potongan 'Top N' ini.`,
|
||||
variable: 'Variabel',
|
||||
variableTip: `Jika Anda menggunakan API dialog, variabel mungkin membantu Anda berbicara dengan klien Anda dengan strategi yang berbeda.
|
||||
Variabel digunakan untuk mengisi bagian 'Prompt Sistem' dalam prompt untuk memberikan petunjuk kepada LLM.
|
||||
'knowledge' adalah variabel yang sangat khusus yang akan diisi dengan potongan yang diambil.
|
||||
Semua variabel dalam 'Prompt Sistem' harus diberi kurung kurawal.`,
|
||||
variableTip: `Digunakan bersama dengan API manajemen asisten obrolan RAGFlow, variabel dapat membantu mengembangkan strategi prompt sistem yang lebih fleksibel. Variabel yang didefinisikan akan digunakan oleh 'Prompt Sistem' sebagai bagian dari prompt untuk LLM. {knowledge} adalah variabel khusus yang dicadangkan, mewakili bagian-bagian yang diperoleh dari basis pengetahuan yang ditentukan, dan semua variabel harus dikelilingi oleh kurung kurawal {} dalam 'Prompt Sistem'. Lihat https://ragflow.io/docs/dev/set_chat_variables untuk detail lebih lanjut.`,
|
||||
add: 'Tambah',
|
||||
key: 'Kunci',
|
||||
optional: 'Opsional',
|
||||
|
||||
@ -156,7 +156,7 @@ export default {
|
||||
rerankPlaceholder: '選択してください',
|
||||
rerankTip: `オプション:Rerankモデルを選択しない場合、システムはデフォルトでキーワードの類似度とベクトルのコサイン類似度を組み合わせたハイブリッド検索方式を採用します。Rerankモデルを設定した場合、ハイブリッド検索のベクトル類似度部分はrerankのスコアに置き換えられます。`,
|
||||
topK: 'トップK',
|
||||
topKTip: `Kチャンクがリランキングモデルに供給されます。`,
|
||||
topKTip: `Rerank modelと一緒に使用する場合、この設定は指定されたreranking modelに送信するテキストのチャンク数を定義します。`,
|
||||
delimiter: `テキストセグメンテーションの区切り文字`,
|
||||
delimiterTip:
|
||||
'デリミタやセパレータは、一つまたは複数の特殊文字で構成できます。複数の文字の場合、バッククォート(``)で囲むようにしてください。たとえば、デリミタを次のように設定した場合: \\n ## ;、テキストは行末、ダブルハッシュ記号(##)、およびセミコロンで分割されます。デリミタを設定する前に、テキストのセグメンテーションとチャンキングのメカニズムを理解していることを確認してください。',
|
||||
@ -340,7 +340,7 @@ export default {
|
||||
sendPlaceholder: 'アシスタントにメッセージを送信...',
|
||||
chatConfiguration: 'チャット設定',
|
||||
chatConfigurationDescription:
|
||||
'特別なナレッジベースのために専用アシスタントを作成しましょう! 💕',
|
||||
'選択したデータセット(知識ベース)にチャットアシスタントを設定してください! 💕',
|
||||
assistantName: 'アシスタント名',
|
||||
assistantNameMessage: 'アシスタント名は必須です',
|
||||
namePlaceholder: '例: 履歴書アシスタント',
|
||||
@ -364,10 +364,7 @@ export default {
|
||||
topN: 'トップN',
|
||||
topNTip: `類似度スコアがしきい値を超えるチャンクのうち、上位N件のみがLLMに供給されます。`,
|
||||
variable: '変数',
|
||||
variableTip: `ダイアログAPIを使用する場合、変数は異なる戦略でクライアントとチャットするのに役立ちます。
|
||||
変数はプロンプトの'システムプロンプト'部分を埋めるために使用され、LLMにヒントを与えます。
|
||||
'ナレッジ'は取得されたチャンクで埋められる非常に特別な変数です。
|
||||
'システムプロンプト'のすべての変数は中括弧で囲む必要があります。`,
|
||||
variableTip: `RAGFlowのチャットアシスタント管理APIと組み合わせて使用することで、変数はより柔軟なシステムプロンプト戦略を開発するのに役立ちます。定義された変数は、LLMのプロンプトの一部として「システムプロンプト」で使用されます。{knowledge}は、指定された知識ベースから取得された部分を表す特別な予約変数であり、「システムプロンプト」ではすべての変数を波括弧{}で囲む必要があります。詳細はhttps://ragflow.io/docs/dev/set_chat_variablesを参照してください。`,
|
||||
add: '追加',
|
||||
key: 'キー',
|
||||
optional: 'オプション',
|
||||
|
||||
@ -161,7 +161,7 @@ export default {
|
||||
rerankTip:
|
||||
'Se deixado vazio, o RAGFlow usará uma combinação de similaridade de palavras-chave ponderada e similaridade de cosseno vetorial ponderada; se um modelo de reranking for selecionado, uma pontuação de reranking ponderada substituirá a similaridade de cosseno vetorial ponderada. Esteja ciente de que usar um modelo de reranking aumentará significativamente o tempo de resposta do sistema.',
|
||||
topK: 'Top-K',
|
||||
topKTip: 'K fragmentos serão alimentados em modelos de reranking.',
|
||||
topKTip: 'Usado em conjunto com o Rerank model, essa configuração define o número de trechos de texto a serem enviados ao modelo reranking especificado.',
|
||||
delimiter: 'Delimitadores para segmentação de texto',
|
||||
delimiterTip:
|
||||
'Um delimitador ou separador pode consistir em um ou vários caracteres especiais. Se for múltiplos caracteres, certifique-se de que estejam entre crases (``). Por exemplo, se você configurar seus delimitadores assim: \\n`##`;, seus textos serão separados em quebras de linha, símbolos de hash duplo (##) ou ponto e vírgula. Defina os delimitadores apenas após entender o mecanismo de segmentação e particionamento de texto.',
|
||||
@ -337,7 +337,7 @@ export default {
|
||||
sendPlaceholder: 'Envie uma mensagem para o assistente...',
|
||||
chatConfiguration: 'Configuração do Chat',
|
||||
chatConfigurationDescription:
|
||||
'Configure aqui um assistente de chat dedicado às bases de conhecimento selecionadas! 💕',
|
||||
'Configure um assistente de bate-papo para os conjuntos de dados selecionados (bases de conhecimento) aqui! 💕',
|
||||
assistantName: 'Nome do assistente',
|
||||
assistantNameMessage: 'O nome do assistente é obrigatório',
|
||||
namePlaceholder: 'Ex.: Jarvis Currículos',
|
||||
@ -363,7 +363,7 @@ export default {
|
||||
topN: 'Top N',
|
||||
topNTip: `Nem todos os fragmentos com pontuação de similaridade acima do 'limiar de similaridade' serão enviados ao LLM. Isso seleciona os 'Top N' fragmentos recuperados.`,
|
||||
variable: 'Variável',
|
||||
variableTip: `As variáveis podem ajudar a desenvolver estratégias mais flexíveis, especialmente ao usar nossas APIs de gerenciamento de assistentes de chat. Essas variáveis serão usadas pelo 'Sistema' como parte dos prompts para o LLM. A variável {knowledge} é uma variável especial reservada que representa suas bases de conhecimento selecionadas, e todas as variáveis devem estar entre chaves { }.`,
|
||||
variableTip: `Usados em conjunto com as APIs de gerenciamento de assistente de bate-papo do RAGFlow, as variáveis podem ajudar a desenvolver estratégias de prompt do sistema mais flexíveis. As variáveis definidas serão usadas pelo 'Prompt do sistema' como parte dos prompts para o LLM. {knowledge} é uma variável especial reservada que representa partes recuperadas de base(s) de conhecimento especificada(s), e todas as variáveis devem ser cercadas por chaves {} no 'Prompt do sistema'. Veja https://ragflow.io/docs/dev/set_chat_variables para mais detalhes.`,
|
||||
add: 'Adicionar',
|
||||
key: 'Chave',
|
||||
optional: 'Opcional',
|
||||
|
||||
@ -161,7 +161,7 @@ export default {
|
||||
rerankPlaceholder: 'Vui lòng chọn',
|
||||
rerankTip: `Nếu để trống, RAGFlow sẽ sử dụng kết hợp giữa độ tương đồng từ khóa được trọng số và độ tương đồng vectơ cosin được trọng số; nếu chọn mô hình xếp hạng lại, điểm xếp hạng được tính lại sẽ thay thế độ tương đồng vectơ cosin được trọng số.`,
|
||||
topK: 'Top-K',
|
||||
topKTip: `K khối sẽ được đưa vào các mô hình xếp hạng lại.`,
|
||||
topKTip: `Sử dụng cùng với Rerank model, thiết lập này xác định số lượng đoạn văn cần gửi đến mô hình reranking được chỉ định.`,
|
||||
delimiter: 'Dấu phân cách cho phân đoạn văn bản',
|
||||
html4excel: 'Excel sang HTML',
|
||||
html4excelTip: `Sử dụng cùng với phương pháp cắt khúc General. Khi chưa được bật, tệp bảng tính (XLSX, XLS (Excel97~2003)) sẽ được phân tích theo dòng thành các cặp khóa-giá trị. Khi bật, tệp bảng tính sẽ được phân tích thành bảng HTML. Nếu bảng gốc vượt quá 12 dòng, hệ thống sẽ tự động chia thành nhiều bảng HTML mỗi 12 dòng.`,
|
||||
@ -383,7 +383,7 @@ export default {
|
||||
sendPlaceholder: 'Nhắn tin cho Trợ lý...',
|
||||
chatConfiguration: 'Cấu hình Chat',
|
||||
chatConfigurationDescription:
|
||||
'Tại đây, hãy trang điểm cho một trợ lý chuyên dụng cho các cơ sở kiến thức đặc biệt của bạn! 💕',
|
||||
'Thiết lập trợ lý trò chuyện cho các tập dữ liệu đã chọn (cơ sở tri thức) tại đây. 💕',
|
||||
assistantName: 'Tên trợ lý',
|
||||
assistantNameMessage: 'Tên trợ lý là bắt buộc',
|
||||
namePlaceholder: 'ví dụ: Resume Jarvis',
|
||||
@ -408,10 +408,7 @@ export default {
|
||||
topN: 'Top N',
|
||||
topNTip: `Không phải tất cả các khối có điểm tương đồng vượt quá 'ngưỡng tương đồng' sẽ được cung cấp cho LLMs. LLM chỉ có thể xem 'Top N' khối này.`,
|
||||
variable: 'Biến',
|
||||
variableTip: `Nếu bạn sử dụng API thoại, các biến có thể giúp bạn trò chuyện với khách hàng của mình bằng các chiến lược khác nhau.
|
||||
Các biến được sử dụng để điền vào phần 'Hệ thống' trong lời nhắc để cung cấp cho LLM một gợi ý.
|
||||
'knowledge' là một biến rất đặc biệt sẽ được điền bằng các khối được truy xuất.
|
||||
Tất cả các biến trong 'Hệ thống' phải được đặt trong dấu ngoặc nhọn.`,
|
||||
variableTip: `Sử dụng cùng với các API quản lý trợ lý trò chuyện của RAGFlow, các biến có thể giúp phát triển các chiến lược lời nhắc hệ thống linh hoạt hơn. Các biến được định nghĩa sẽ được sử dụng bởi 'Lời nhắc hệ thống' như một phần của lời nhắc cho LLM. {knowledge} là một biến đặc biệt được bảo lưu, đại diện cho các phần được truy xuất từ cơ sở tri thức được chỉ định, và tất cả các biến nên được đặt trong ngoặc nhọn {} trong 'Lời nhắc hệ thống'. Xem https://ragflow.io/docs/dev/set_chat_variables để biết thêm chi tiết.`,
|
||||
add: 'Thêm',
|
||||
key: 'Khóa',
|
||||
optional: 'Tùy chọn',
|
||||
|
||||
@ -159,7 +159,7 @@ export default {
|
||||
rerankPlaceholder: '請選擇',
|
||||
rerankTip: `如果是空的。它使用查詢和塊的嵌入來構成矢量餘弦相似性。否則,它使用rerank評分代替矢量餘弦相似性。`,
|
||||
topK: 'Top-K',
|
||||
topKTip: `K塊將被送入Rerank型號。`,
|
||||
topKTip: `與 Rerank 模型配合使用,用於設定傳給 Rerank 模型的文本塊數量。`,
|
||||
delimiter: `文字分段標識符`,
|
||||
delimiterTip:
|
||||
'支持多字符作為分隔符,多字符用 `` 分隔符包裹。若配置成:\\n`##`; 系統將首先使用換行符、兩個#號以及分號先對文本進行分割,隨後再對分得的小文本塊按照「建议文本块大小」設定的大小進行拼裝。在设置文本分段標識符之前,請確保您已理解上述文本分段切片機制。',
|
||||
@ -401,7 +401,7 @@ export default {
|
||||
send: '發送',
|
||||
sendPlaceholder: '消息概要助手...',
|
||||
chatConfiguration: '聊天配置',
|
||||
chatConfigurationDescription: '在這裡,為你的專業知識庫裝扮專屬助手!💕',
|
||||
chatConfigurationDescription: '為你的知識庫配置專屬聊天助手!💕',
|
||||
assistantName: '助理姓名',
|
||||
assistantNameMessage: '助理姓名是必填項',
|
||||
namePlaceholder: '例如 賈維斯簡歷',
|
||||
@ -427,10 +427,9 @@ export default {
|
||||
topN: 'Top N',
|
||||
topNTip: `並非所有相似度得分高於“相似度閾值”的塊都會被提供給法學碩士。LLM 只能看到這些“Top N”塊。`,
|
||||
variable: '變量',
|
||||
variableTip: `如果您使用对话 API,变量可能会帮助您使用不同的策略与客户聊天。
|
||||
这些变量用于填写提示中的“系统提示词”部分,以便给LLM一个提示。
|
||||
“知识”是一个非常特殊的变量,它将用检索到的块填充。
|
||||
“系统提示词”中的所有变量都应该用大括号括起来。`,
|
||||
variableTip: `你可以透過對話 API,並配合變數設定來動態調整大模型的系統提示詞。
|
||||
{knowledge}為系統預留變數,代表從指定知識庫召回的文本塊。
|
||||
「系統提示詞」中的所有變數都必須用大括號{}括起來。詳見 https://ragflow.io/docs/dev/set_chat_variables。`,
|
||||
add: '新增',
|
||||
key: '關鍵字',
|
||||
optional: '可選的',
|
||||
|
||||
@ -159,7 +159,7 @@ export default {
|
||||
rerankPlaceholder: '请选择',
|
||||
rerankTip: `非必选项:若不选择 rerank 模型,系统将默认采用关键词相似度与向量余弦相似度相结合的混合查询方式;如果设置了 rerank 模型,则混合查询中的向量相似度部分将被 rerank 打分替代。请注意:采用 rerank 模型会非常耗时。`,
|
||||
topK: 'Top-K',
|
||||
topKTip: `K块将被送入Rerank型号。`,
|
||||
topKTip: `与 Rerank 模型配合使用,用于设置传给 Rerank 模型的文本块数量。`,
|
||||
delimiter: `文本分段标识符`,
|
||||
delimiterTip:
|
||||
'支持多字符作为分隔符,多字符用 `` 分隔符包裹。若配置成:\\n`##`; 系统将首先使用换行符、两个#号以及分号先对文本进行分割,随后再对分得的小文本块按照「建议文本块大小」设定的大小进行拼装。在设置文本分段标识符前请确保理解上述文本分段切片机制。',
|
||||
@ -418,7 +418,7 @@ General:实体和关系提取提示来自 GitHub - microsoft/graphrag:基于
|
||||
send: '发送',
|
||||
sendPlaceholder: '消息概要助手...',
|
||||
chatConfiguration: '聊天配置',
|
||||
chatConfigurationDescription: '在这里,为你的专业知识库装扮专属助手! 💕',
|
||||
chatConfigurationDescription: '为你的知识库配置专属聊天助手! 💕',
|
||||
assistantName: '助理姓名',
|
||||
assistantNameMessage: '助理姓名是必填项',
|
||||
namePlaceholder: '例如 贾维斯简历',
|
||||
@ -444,10 +444,9 @@ General:实体和关系提取提示来自 GitHub - microsoft/graphrag:基于
|
||||
topN: 'Top N',
|
||||
topNTip: `并非所有相似度得分高于“相似度阈值”的块都会被提供给大语言模型。 LLM 只能看到这些“Top N”块。`,
|
||||
variable: '变量',
|
||||
variableTip: `如果您使用对话 API,变量可能会帮助您使用不同的策略与客户聊天。
|
||||
这些变量用于填写提示中的“系统提示词”部分,以便给LLM一个提示。
|
||||
“知识”是一个非常特殊的变量,它将用检索到的块填充。
|
||||
“系统提示词”中的所有变量都应该用大括号括起来。`,
|
||||
variableTip: `你可以通过对话 API,并配合变量设置来动态调整大模型的系统提示词。
|
||||
{knowledge}为系统预留变量,代表从指定知识库召回的文本块。
|
||||
“系统提示词”中的所有变量都必须用大括号{}括起来。详见 https://ragflow.io/docs/dev/set_chat_variables。`,
|
||||
add: '新增',
|
||||
key: '关键字',
|
||||
optional: '可选的',
|
||||
|
||||
@ -37,9 +37,9 @@ const validateMessages = {
|
||||
};
|
||||
|
||||
enum ConfigurationSegmented {
|
||||
AssistantSetting = 'Assistant Setting',
|
||||
PromptEngine = 'Prompt Engine',
|
||||
ModelSetting = 'Model Setting',
|
||||
AssistantSetting = 'Assistant settings',
|
||||
PromptEngine = 'Prompt engine',
|
||||
ModelSetting = 'Model settings',
|
||||
}
|
||||
|
||||
const segmentedMap = {
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user